Google Maps is optimized to find your way from A to B. In your meetings you usually want to achieve the same. That’s why, suprisingly, Google Maps gives you perfect guidance on how to drive your meetings:
Use your imagination, visualize!
Imagine “Google Maps” without a visual map! Would you use it? No way! A picture says more than 1000 words . It helps your brain to get an overview. It is a foundation for your conversations.
Start with where you are
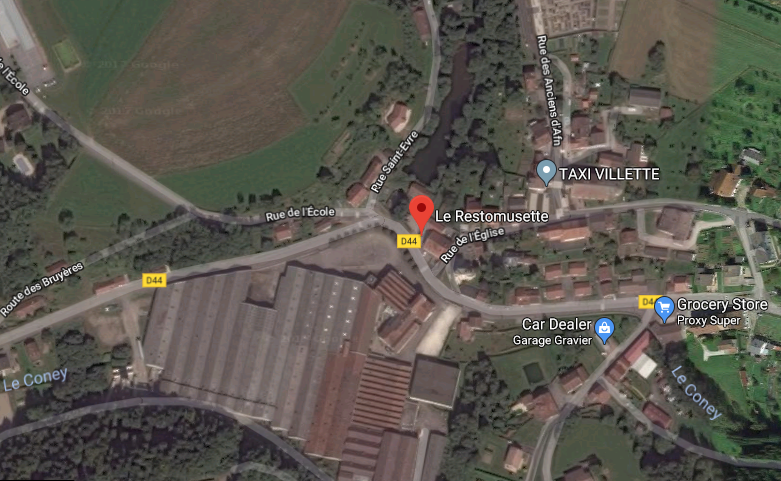 Put all people into your context so they can see what you are talking about. Describe what your current situation is. Possibly you want to include what was already achieved, what is working well, and what things are missing or hurting yet.
Put all people into your context so they can see what you are talking about. Describe what your current situation is. Possibly you want to include what was already achieved, what is working well, and what things are missing or hurting yet.
Examples:
- Current state of your software architecture. Requirements already fulfilled by your application. Issues that you are currently facing, or what is not currently possible to do.
Define where you want to go
 State a clear goal where you are about to head. By this I don’t meant the objective of the meeting. Your google maps consultation’s objective is not Prague. It is to find the route to go to Prague.
State a clear goal where you are about to head. By this I don’t meant the objective of the meeting. Your google maps consultation’s objective is not Prague. It is to find the route to go to Prague.
Examples:
- New requirements that need to be built in. What specifically is needed in your application to fulfill this requirement?
Zoom out (this is automatically done by Google Maps once you entered your destination)
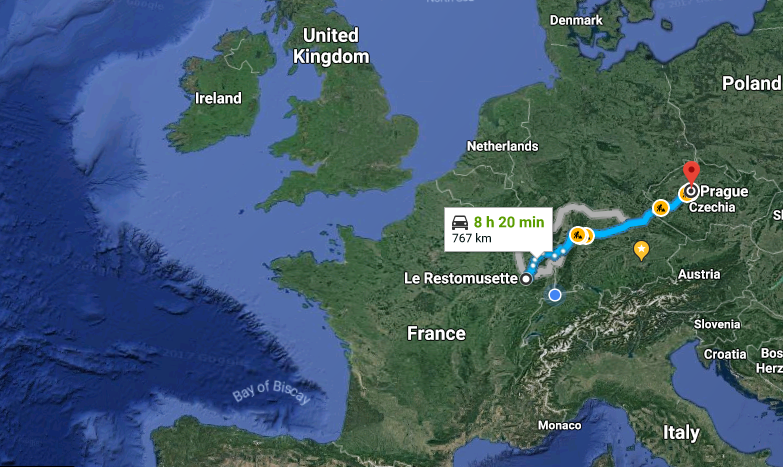 Start to gather ideas; this is a “divergent” phase: It may seem a bit chaotic and not be clearly targetted towards the objective of the meeting. What’s important here is to get everything possibly important on the table: What problems could you face? What people could be involved? What tools, hints, solutions come to mind? What problems are related and may need to be considered? Etc.
Start to gather ideas; this is a “divergent” phase: It may seem a bit chaotic and not be clearly targetted towards the objective of the meeting. What’s important here is to get everything possibly important on the table: What problems could you face? What people could be involved? What tools, hints, solutions come to mind? What problems are related and may need to be considered? Etc.
Visualize everything. You can paste sticky notes on a wall, draw all ideas into a single visualization on a whiteboard or whatever you see(!) fit.
Find possible routes
Of course Google Maps also does this for you:
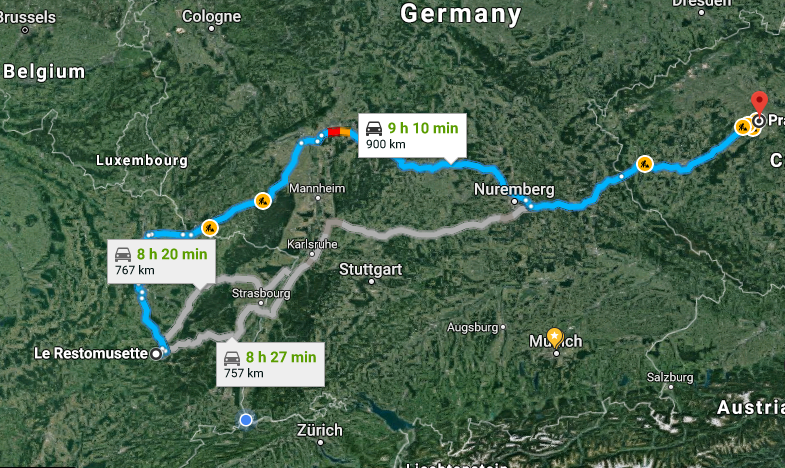
Try to cluster all the gathered data in some ways to condense them into 3-5 sketched solutions. Don’t try to do everything on your own. All people in the room should participate. You only faciliate this by moving around sticky notes, drawing stuff on your “map”, etc.
Assess the routes
For each route in Google Map you can see kilometers, hours and minutes, construction sites and more on the map.



List the advantages, disadvantages, risks and assumptions of each suggested solution. Of course, again, you do this together with all the people in the room.
Decide on a route and generate directions.
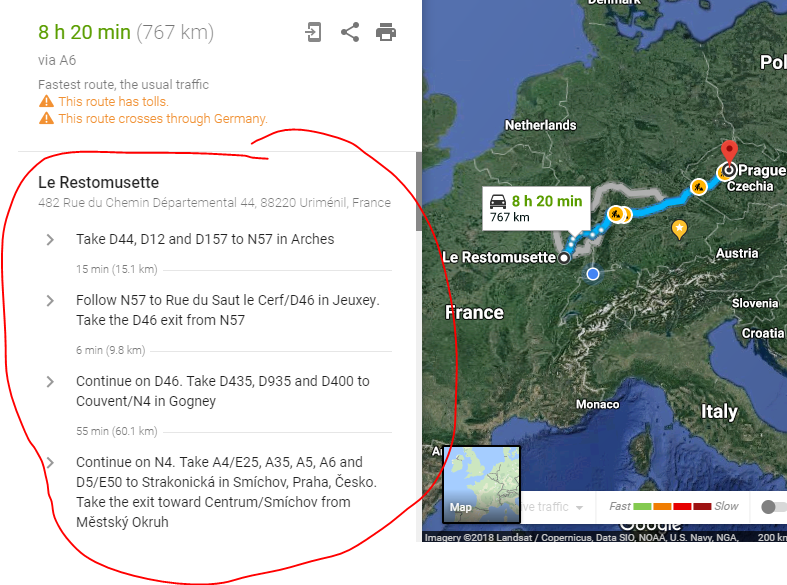
List the action items required. Each action item must be a clear and comlete sentence. E.g. instead of “finance”, state “Ask finance whether XY would be a good fit for them.” Furthermore, each action item must have a timeline and a name assigned, otherwise it will only fill some space in your Wiki but never be executed.
After the meeting: Continuously reassess your planned route and adapt it if necessary.
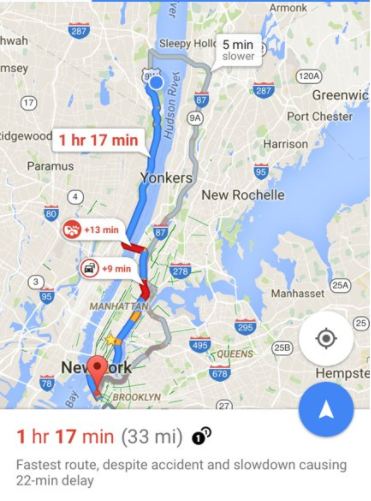
Things “can” not change, they will! You may need to replan action items or even change the route – let alone the shifts of the goal itself.



